JVM调优案例
Contents
老年代晋升速率优化
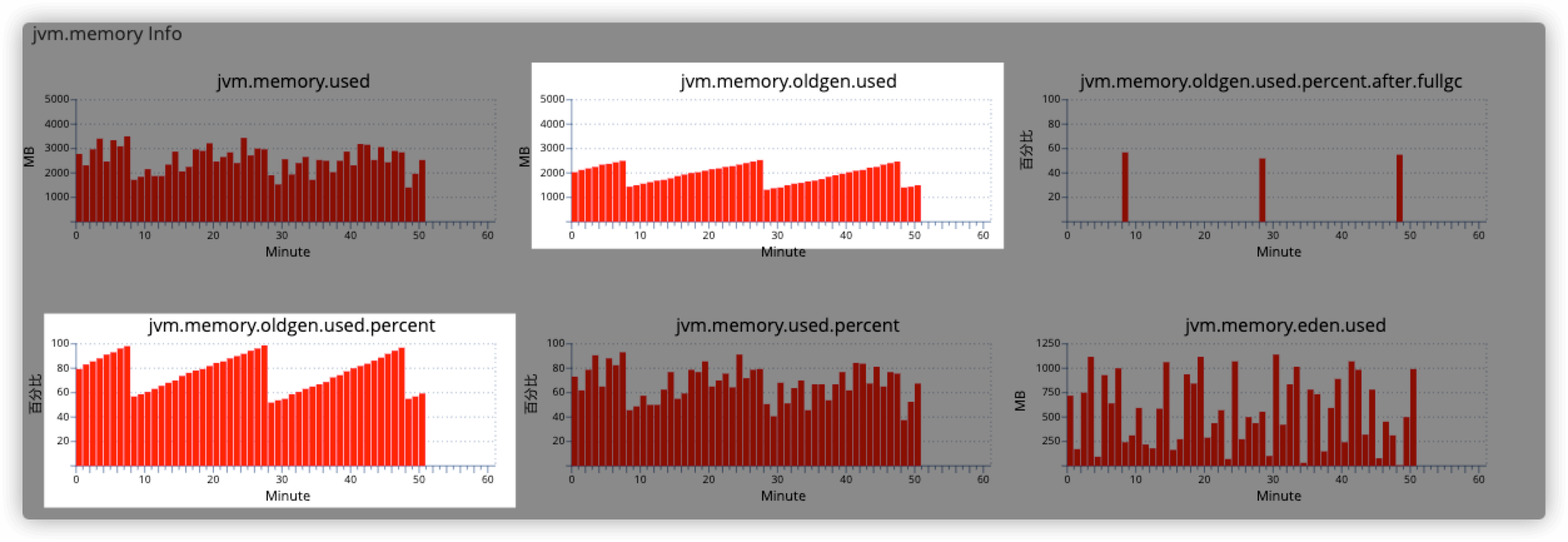
从监控上可以看到,老年代的增长速率比较高,一个小时内出现了三次full gc。
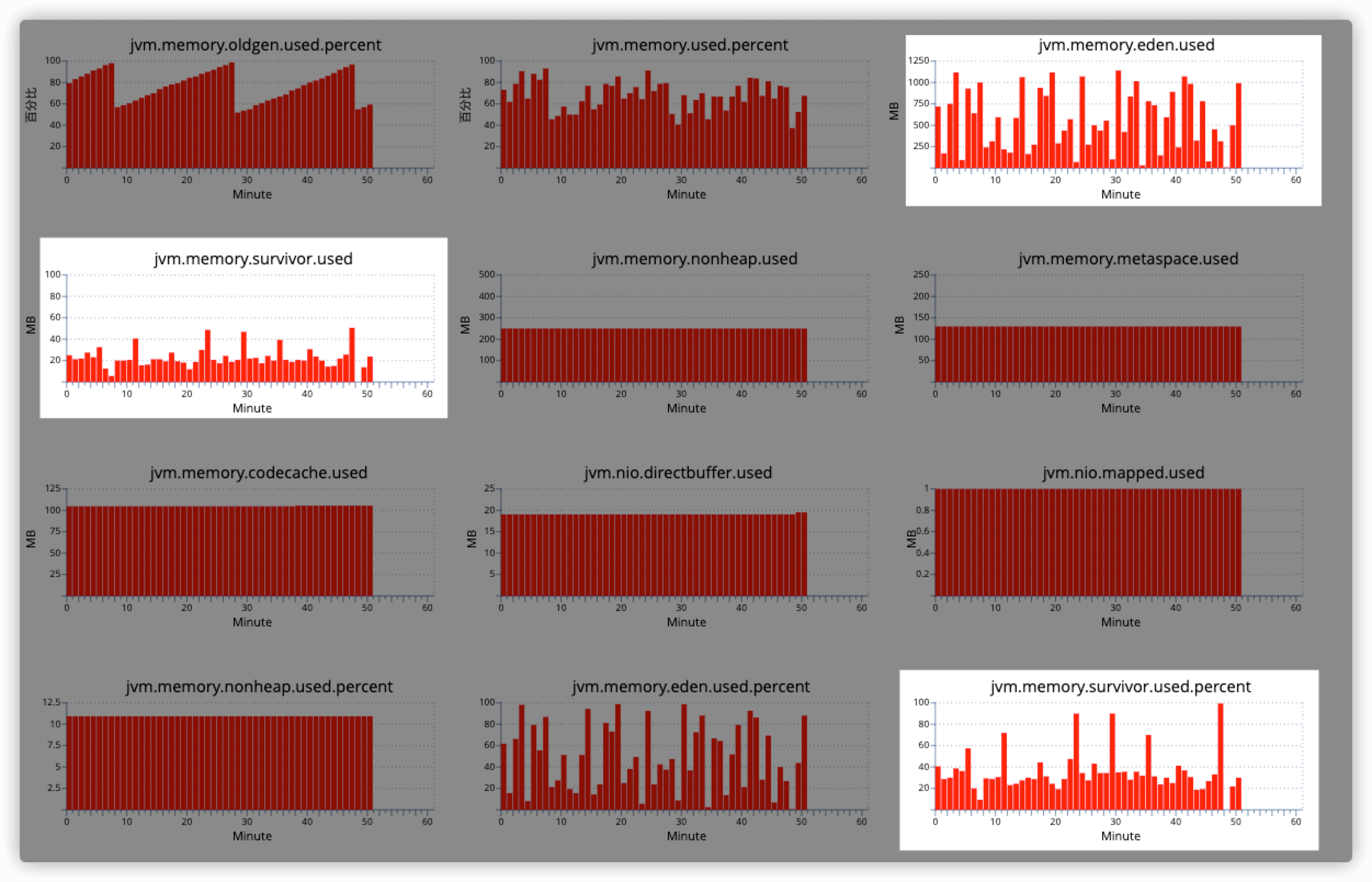
这里可以看到survivor使用率到达100%时,survivor才使用了50m左右,和eden区的比例,很明显不是8:2的关系。
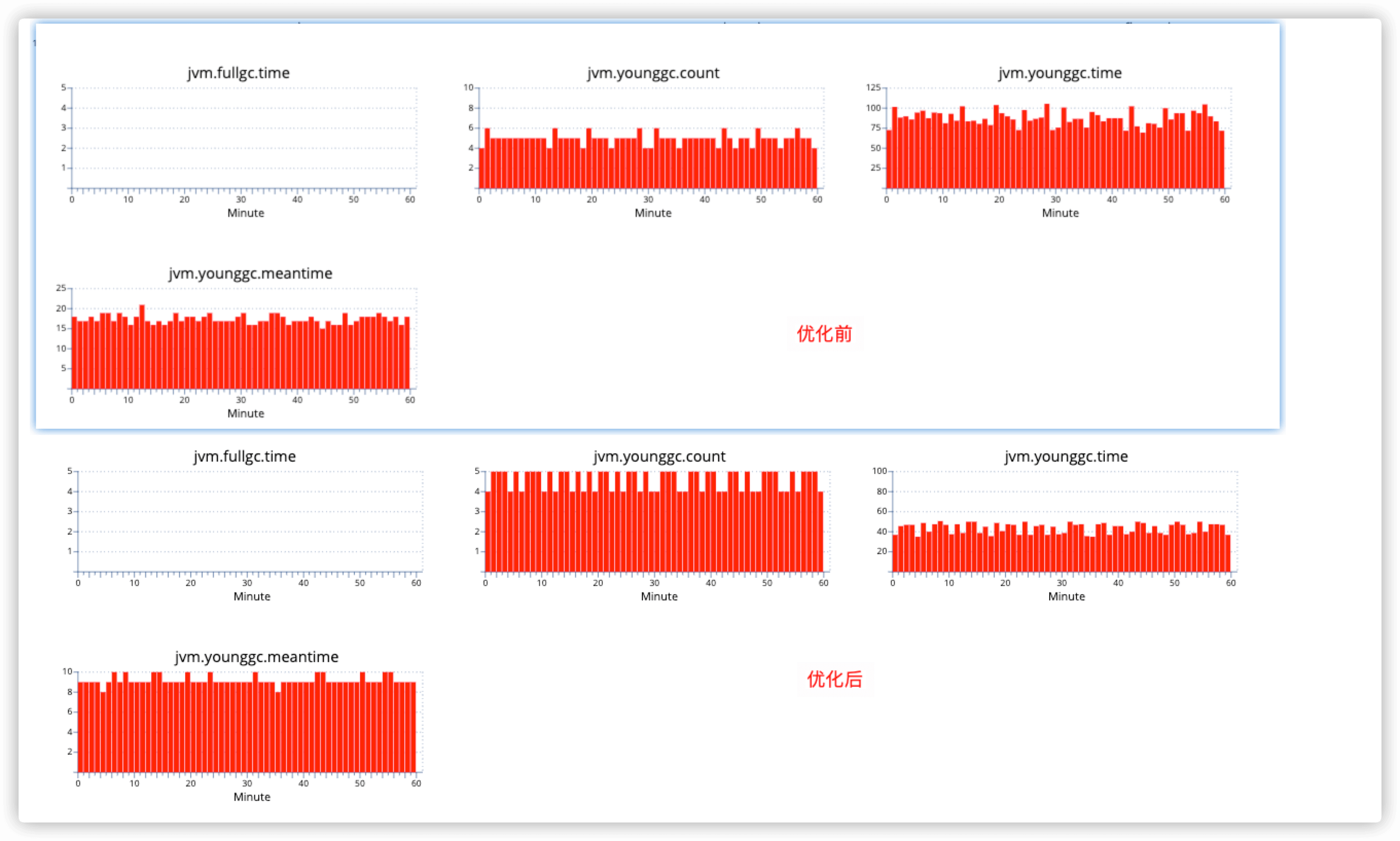
问题的原因在于此服务使用了Parallel Scavenge垃圾回收器,默认会开启UseAdaptiveSizePolicy自适应优化功能,可以动态调整堆大小和eden区survivor区比值。这里选择关闭自适应优化-XX:-UseAdaptiveSizePolicy。
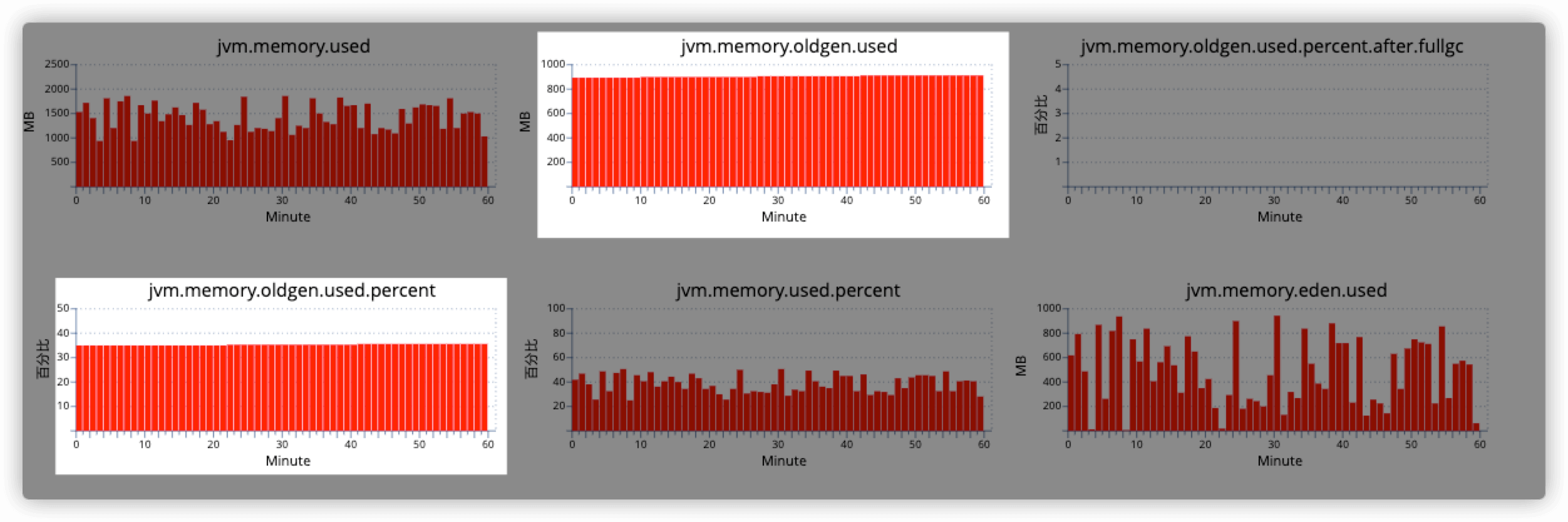
可以看到,老年代的增长数据变得相对稳定很多,在Minor GC方面,两者差距不是很大。
老年代突增优化

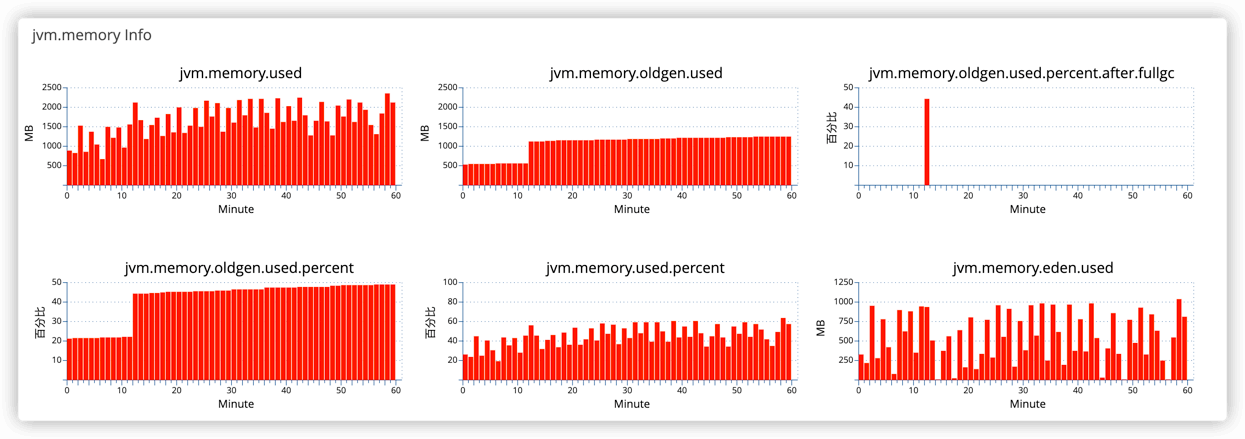
上面在优化的过程中,无论从CAT还是GC日志,都出现了老年代突增的异常。情况出现的频率不是很高,所以开启JFR进行监控。
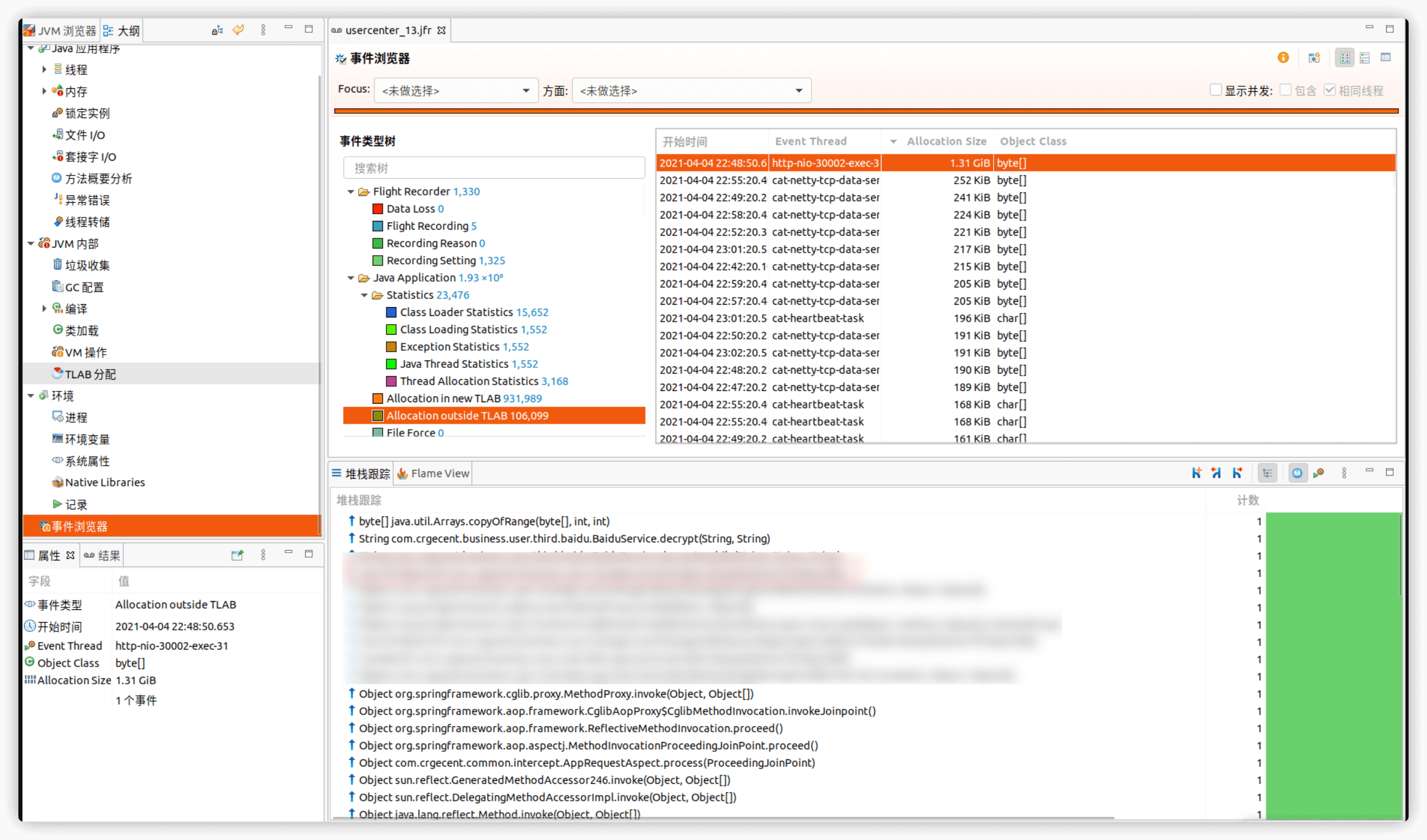
可以看到,有一次分配了1.31G的对象,此接口曾经出现oom现象,当时并未怀疑此接口导致的OOM。此时用当时的日志请求参数尝试。
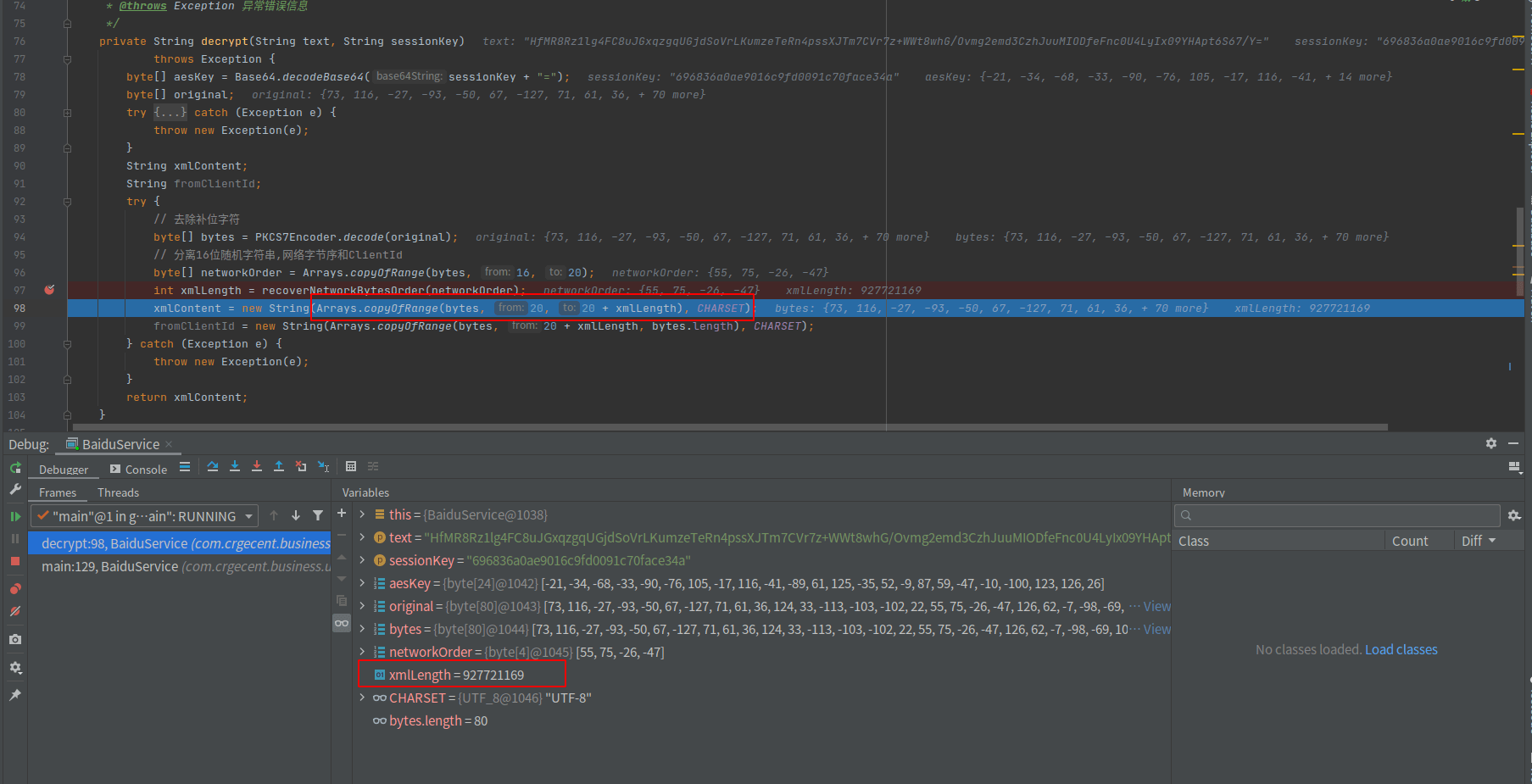
这是一段第三方对接示例代码,在某种情况下会导致数据异常,创建了一个超大数组。
finalize对象优化
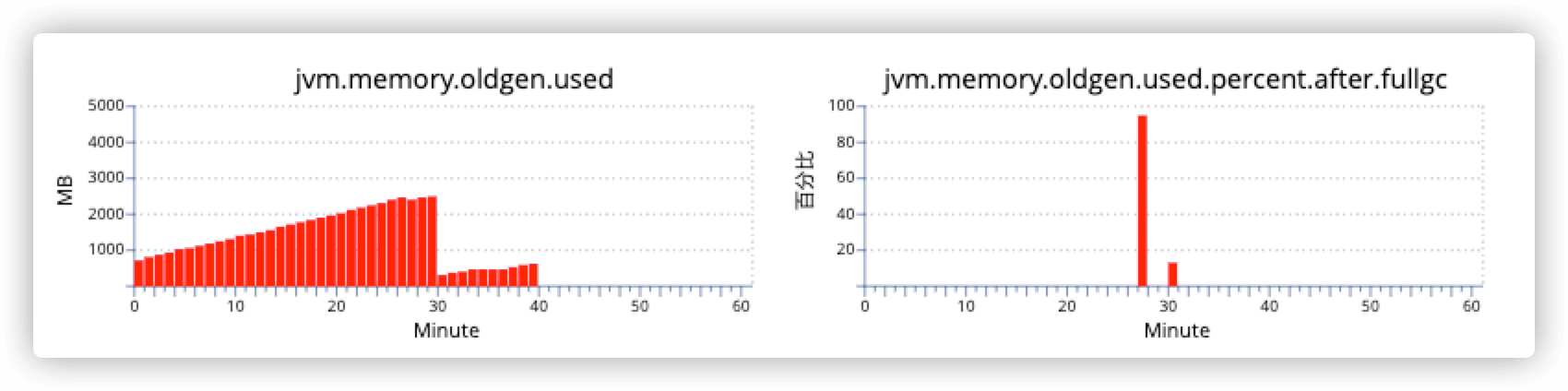
一开始关注这个项目就是因为项目在Full GC后无法回收足够的空间,第二次Full GC则不然,如果有经验的话,应该可以猜到是finalize对象导致GC很难回收空间。
如果一个对象实现了finalize方法,在GC的时候并不会直接清理对象,只是简单标记下,然后在GC结束后,会和用户线程并行执行,并调用finalize方法,下次GC的时候会清理哪些已经被调用finalize方法的对象。
如果老年代里的对象80%都是实现了finalize方法,那么第一次GC,理论上GC后的内存占用率会大于80%。
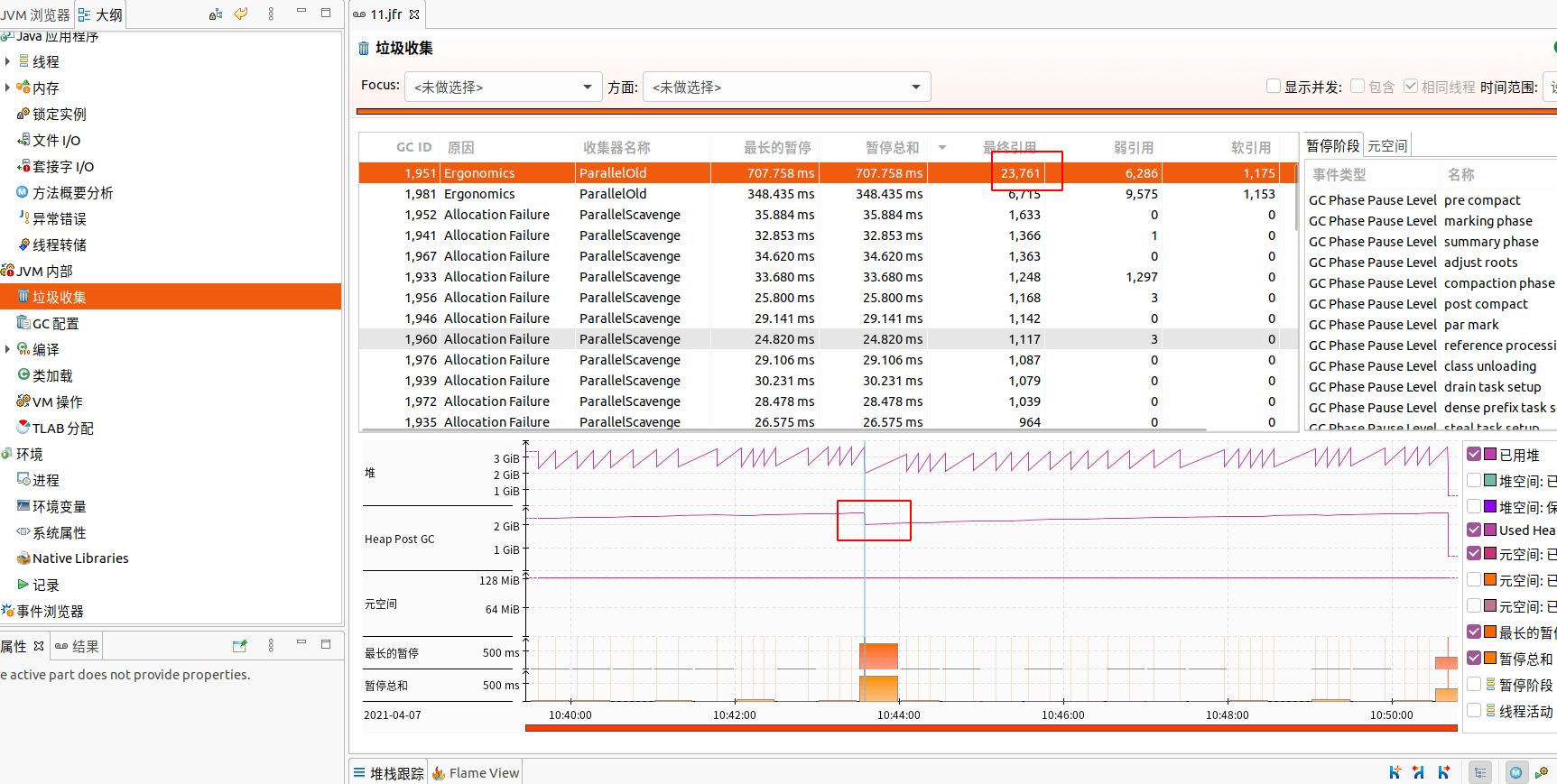
这里从JFR里也侧面印证我们的猜测。
这里确定对象最简单的方法就是获取一个堆快照,分析是哪些对象,比较常见的就是socket类。事实上从堆文件里也印证了猜测。确定了问题,接下来就是确定优化的代码,我们也可以从JFR里分析。
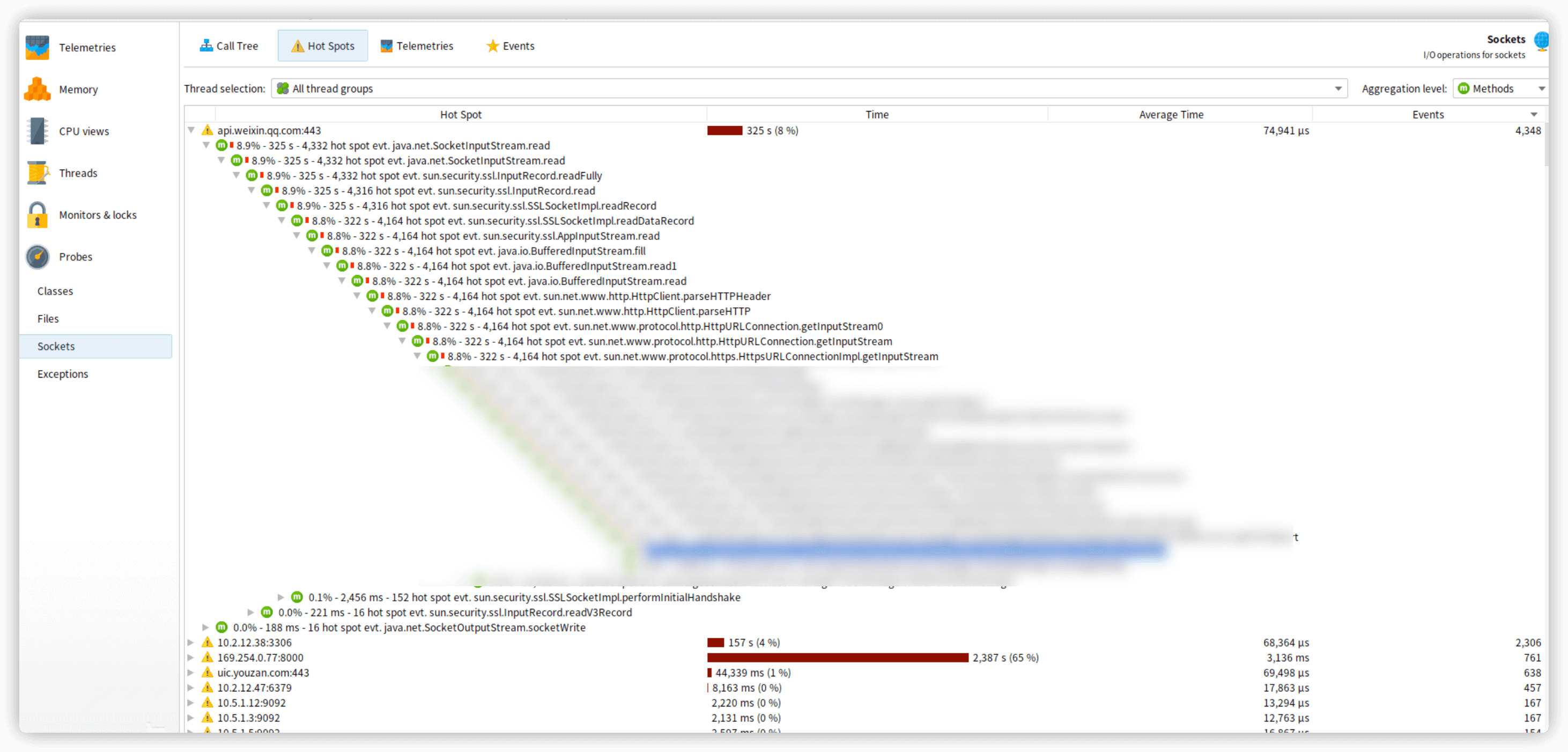
按照采样到次数降序进行排查,很容易找到要优化的代码。
上面说过是因为socket的原因,我们应该减少创建这种GC负担比较重的对象,所以应该使用连接池,很明显应用程序应该没有对连接进行复用。项目连接使用的是JDK自带的HttpsURLConnection,默认是可以复用连接,代码如下:
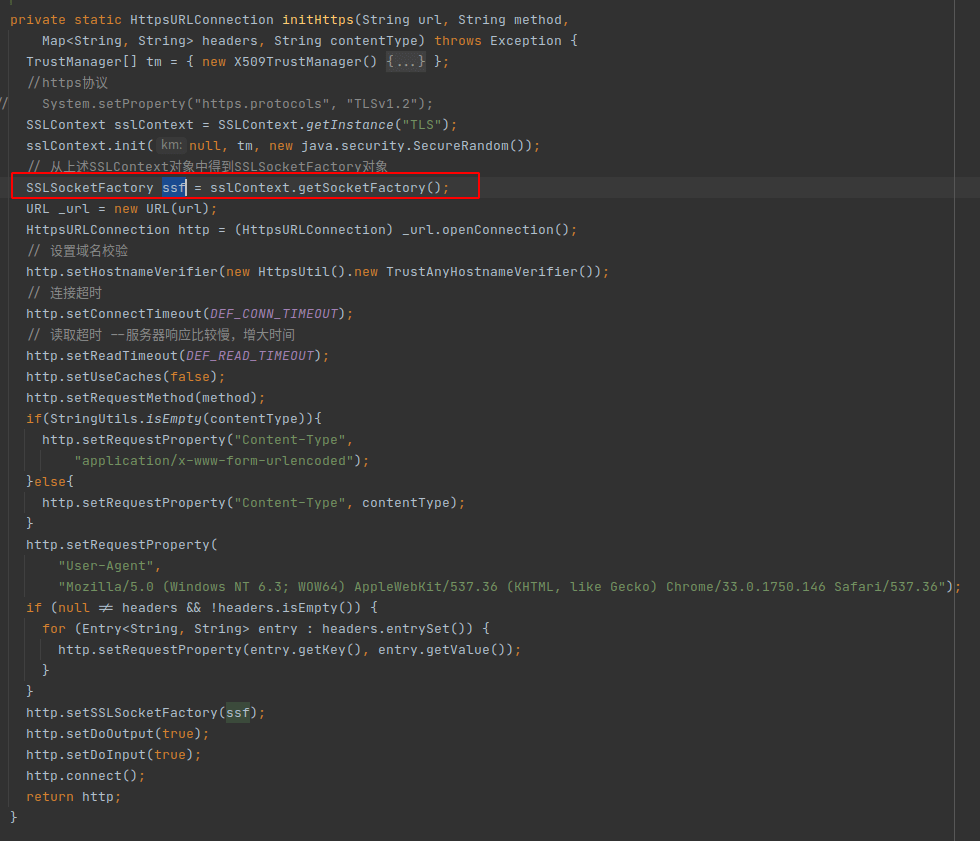
这里原因在于每次使用的不同的SSLSocketFactory,这里只需要将ssf修改为单例使用即可。如果要使socket能够复用,要处理许多异常情况,所以比较建议使用第三方库简化使用,这里使用OkHttp。
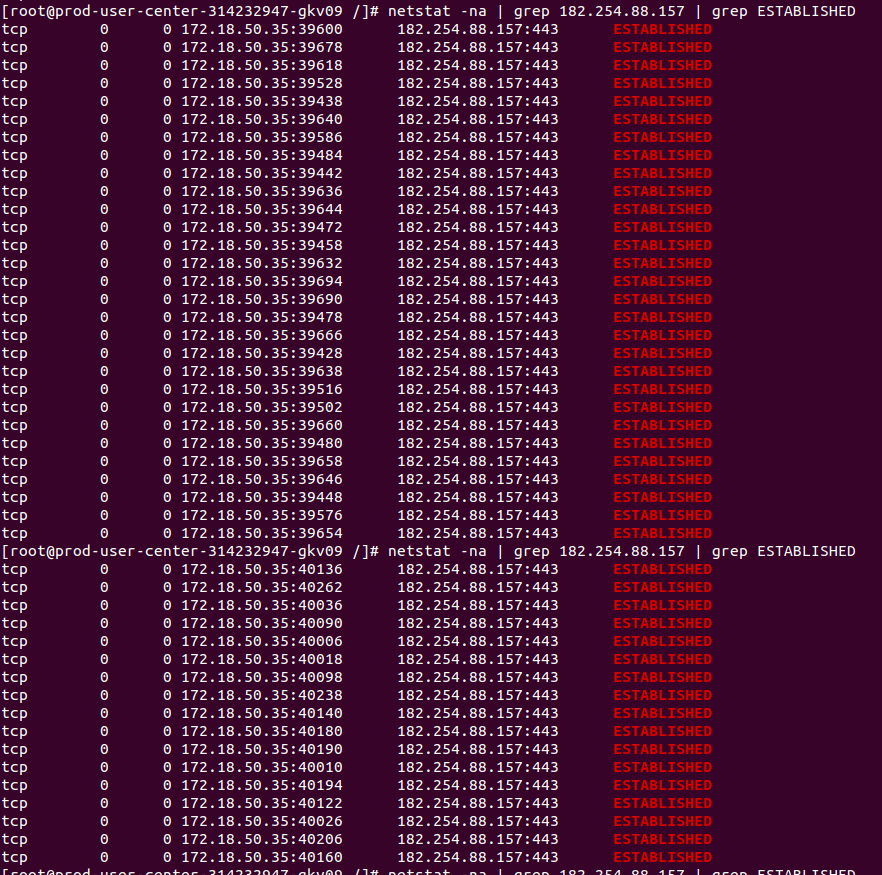
下面是未重用连接前的情况,还有很多time wait的连接,每次请求都创建一个新的socket,可以从端口号看出
下面是优化后的情况
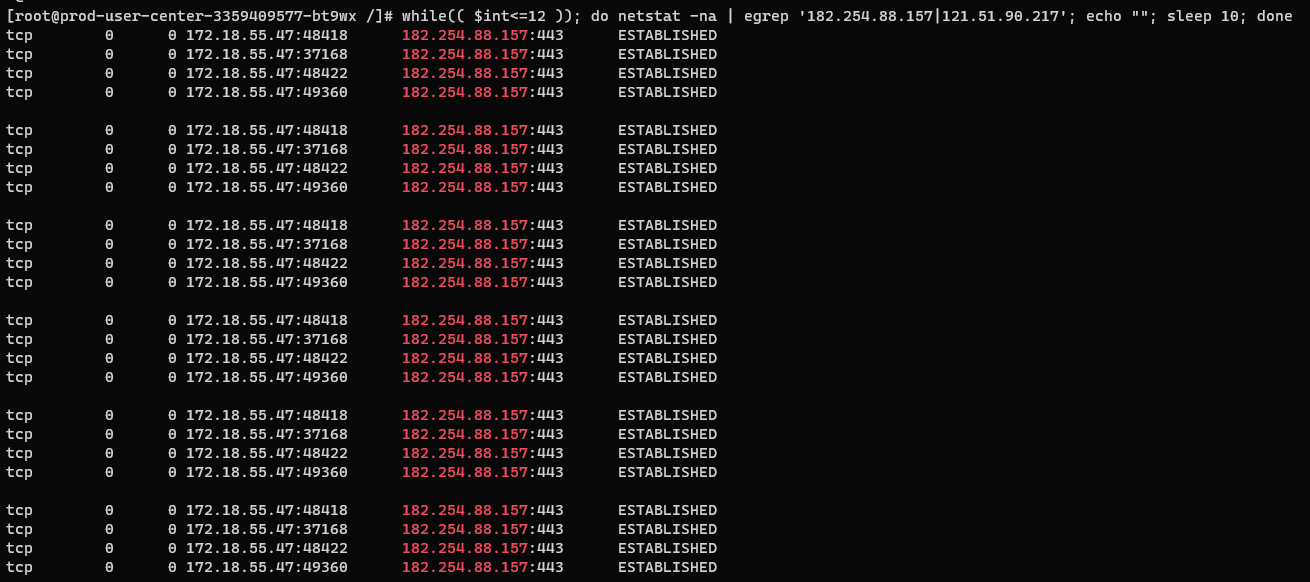
对应接口的50线,95线,99.9线接口请求减少了15ms。从网络角度,每次握手需要1.5RTT握手,2RTT的TSL1.2握手,至少多出3RTT时延。
Author: Abely Liu
Link: http://abely.cn/2021/04/07/JVM%E8%B0%83%E4%BC%98%E6%A1%88%E4%BE%8B/
License: 知识共享署名-非商业性使用 4.0 国际许可协议